

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/machinelearning by /u/eamonnkeogh on 2024-11-08 23:58:19+00:00.
Dear Colleagues
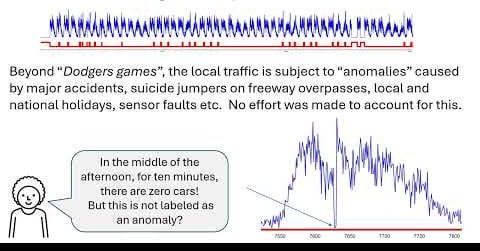
Time Series Anomaly Detection (TSAD) is hot right now, with dozens of papers each year in NeurIPS, SIGKDD, ICML, PVLDB etc.
However, I claim that much of the published results are meaningless, because the uncertainty of the ground truth labels dwarfs any claimed differences between algorithms or amount of claimed improvements.
I have made two 90-second-long videos that make this clear in a visual and intuitive way:
1) Why Most Time Series Anomaly Detection Results are Meaningless (Dodgers)
2) Why Most Time Series Anomaly Detection Results are Meaningless (AnnGun)
As always, corrections and comments welcome.
Eamonn
EDIT: To be clear, my point is simply to prevent others from wasting time working with datasets with essentially random labels. In addition, we should be cautious of any claims in the literature that are based on such data (and that includes at least dozens of highly cited papers)
For a review of most of the commonly used TSAD datasets, see this file: