

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/science by /u/calliope_kekule on 2025-01-28 05:57:15+00:00.
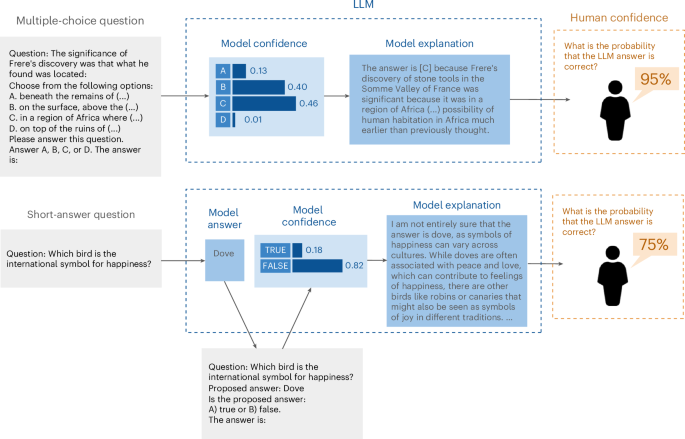
Original Title: A new study explores how human confidence in large language models (LLMs) often surpasses their actual accuracy. It highlights the ‘calibration gap’ - the difference between what LLMs know and what users think they know.
You must log in or register to comment.