
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/dr_lm on 2024-08-27 17:35:33+00:00.
TLDR: this produces a low-res grid of faces in one gen (for high consistency per seed), then crops each cell of the grid and upscales it into high-res gen to use in LoRA training.
Given we currently lack decent controlnets and IPAdapters for Flux, our only option for consistent characters between different seeds and prompts is to train a character LoRA.
Generating training images is a challenge. We want consistency in each training image, but changing seed will change the face. Rendering multiple faces on one seed is a good solution, but then the resolution is too low for training.
This workflow is in three parts:
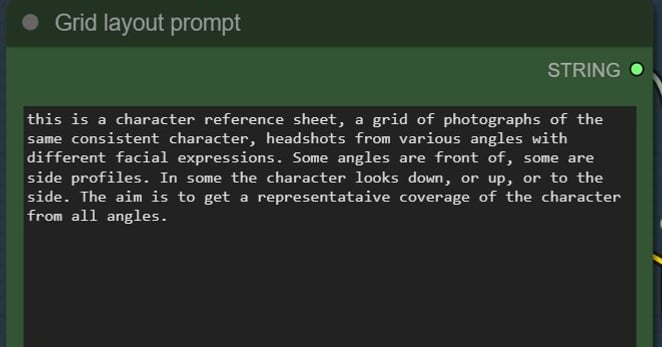
1 Generate a grid of faces, which will be consistently of the same person. Do this at low-res.
Prompt:
Low-res pass:
2 Automatically crop out each face, put it into a list.
3 Render a high-res pass of each grid cell (face) using img2img.
The consistency is not perfect, even in the first pass, but it’s an improvement on what I can get by rendering faces with the same prompt over different seeds. A LoRA trained on these images will learn the average of them all, and I think the consistency is good enough for those purposes. The aim isn’t to remove all differences between images, but to have a good degree of control over how the character looks in the final LoRA. The second-pass denoise is critical here.
Nothing fancy is happening here, instead the focus is on automation. Once you have a seed that a) makes a nice tidy grid, and b) has a character look that you like, you can fix that seed and slightly alter the prompt (e.g. make their expression “angry” or “happy”, change hairstyles or clothes) without losing much consistency.
Some notes/tips:
- I’ve tried to keep the spaghetti within each stage, hopefully the connections and flow between stages are fairly clear. It should be modular, if you wanted to swap in or out particular parts.
- I’m trying to use the xlabs canny controlnet (v2) to guide the shape of the grid. It doesn’t work very well, YMMV, consider turning it off.
- Try different seeds until you get a workable grid layout. Flux will sometimes create nice uniform grids, and sometimes a more random layout that won’t crop nicely. In my experience, it’s better to just find a seed that works rather than prompt-engineer your way to success.
- Depending on the grid you get, you can select two ways of cropping each cell, using either a segm “person” model (whole body) or a bbox “face” model. You can connect whatever version works best for a particular seed on the workflow (there’s a note indicating where).
- You can set the grid width and height, but there’s no guarantee Flux will obey it! It does seem to give the model something to work with, even if you choose not to use controlnet (as the grid is used as a 100% denoised latent for the initial generation).
- The upscale pass should in theory give better consistency if done as a batch, rather than a list. However, you need the VRAM to handle this. On my 25gb 3090, I can do a 4x5 grid of 20 cells in a batch at 1024x1024 using a Q5 flux quant. If you run into VRAM issues, just use a list instead of a batch (there’s a note in the workflow showing where).
- Flux is weird with img2img compared to SD. It needs very high denoise values (>70%) to achieve what SDXL does at ~30%. As with any upscale, the denoise in the upscale pass is critical.
- Because rendering 20 images in the upscale pass is slow, there’s a node to select a subset of the images for testing.
- I use higher steps for the first pass grid (32 seems to work well) than for the upscale (25). I think Flux needs more steps to converge on a tidy layout when making a complex grid. YMMV.
- I use separate guidance (fake Flux cfg) for each pass. As with steps, higher is needed for the first pass.
- There are separate text boxes for the grid layout itself, and for the character. The first pass concats both, the second pass only uses the character prompt. If you want a certain style (e.g. “photograph”, “anime”), make sure it’s at minimum in the character prompt, as otherwise Flux will decide on its own style in the second pass.
- This workflow will work with SD1.5/SDXL models, but there we have far better options with controlnets for pose and grid layout, and IP adapter for consistency, so you can probably achieve more with a different approach. This is flux-specific so I can generate LoRA training images whilst I wait for all that stuff to become available.